पाठ्यक्रम: GS3/ विज्ञान और प्रौद्योगिकी
संदर्भ
- बेंगलुरु-स्थित स्टार्टअप सर्वम AI ने दो स्वदेशी विशाल भाषा मॉडल (LLMs) प्रस्तुत किए, जो वैश्विक प्रतिस्पर्धा के बीच भारत के सार्वभौमिक, बहुभाषी और संगणनात्मक रूप से दक्ष कृत्रिम बुद्धिमत्ता (AI) की दिशा में प्रयासों को रेखांकित करते हैं।
विशाल भाषा मॉडल (LLMs)
- एक विशाल भाषा मॉडल (LLM) कृत्रिम बुद्धिमत्ता (AI) का ऐसा एल्गोरिद्म है जो गहन शिक्षण तकनीकों और अत्यधिक बड़े डाटा सेट का उपयोग करके सामग्री को समझने, संक्षेपित करने, उत्पन्न करने एवं नई सामग्री का पूर्वानुमान लगाने में सक्षम होता है।
- गहन शिक्षण असंरचित डाटा का प्रायिक विश्लेषण करता है, जिससे मॉडल बिना मानवीय हस्तक्षेप के विभिन्न प्रकार की सामग्री के बीच अंतर पहचानने में सक्षम होता है।
- यह समझने में सहायता करता है कि अक्षर, शब्द और वाक्य एक साथ कैसे कार्य करते हैं।
भारत में स्वदेशी LLM पारिस्थितिकी तंत्र
- सर्वम AI मॉडल: दक्षता, सटीकता और भारतीय भाषाओं की क्षमता पर केंद्रित। इन्हें मुक्त-स्रोत बनाने का उद्देश्य है, यद्यपि व्यापक सार्वजनिक परीक्षण जारी है।
- भारतजेन: IIT बॉम्बे में विकसित, जिसने शिक्षा और स्वास्थ्य जैसे क्षेत्रों के लिए बहुभाषी 17-बिलियन-पैरामीटर मॉडल प्रशिक्षित किया।
- ज्ञानी.ai(Gnani.ai): संक्षिप्त भाषण और पाठ-से-भाषण मॉडल प्रस्तुत किए।
LLMs का प्रशिक्षण कैसे होता है?
- GPU क्लस्टर: LLM प्रशिक्षण के लिए अत्यधिक संगणनात्मक शक्ति की आवश्यकता होती है, जिसमें ग्राफिक्स प्रोसेसिंग यूनिट्स (GPUs) के क्लस्टर का उपयोग किया जाता है। हज़ारों GPUs सप्ताहों या महीनों तक एक साथ कार्य करते हैं।
- डाटा मुख्य इनपुट के रूप में: प्रशिक्षण विशाल डाटा सेट पर आधारित होता है, जो प्रायः इंटरनेट से संकलित किए जाते हैं।
- मॉडल पैरामीटर: पैरामीटर आंतरिक भार को दर्शाते हैं जिनके माध्यम से मॉडल पैटर्न सीखते हैं। सर्वम AI ने 35 बिलियन और 105 बिलियन पैरामीटर वाले मॉडल प्रशिक्षित किए।
- अधिक पैरामीटर क्षमता को बढ़ाते हैं, किंतु अधिक संगणनात्मक शक्ति की आवश्यकता होती है।
प्रमुख प्रशिक्षण पद्धतियाँ
- डाटा संकलन: भारतीय भाषाओं में उच्च-गुणवत्ता वाले डाटा सेट एकत्रित करना।
- इसमें सरकारी दस्तावेज़, साहित्य, मीडिया और कृत्रिम डाटा निर्माण शामिल है।
- यह अंग्रेज़ी-केंद्रित AI प्रणालियों से आगे प्रदर्शन सुधारने के लिए महत्वपूर्ण है।
- पूर्व-प्रशिक्षण (Pre-Training): मॉडल बड़े असंरचित डाटा सेट में आगामी टोकन की भविष्यवाणी करके सामान्य भाषा पैटर्न सीखते हैं।
- यह चरण तर्क और व्याकरण की आधारभूत क्षमता विकसित करता है।
- सूक्ष्म-प्रशिक्षण (Fine-Tuning): मॉडल को विशिष्ट कार्यों के लिए संकलित डाटा सेट का उपयोग करके अनुकूलित किया जाता है।
- हगिंग फेस(Hugging Face) और लैंगचेन(LangChain) जैसे उपकरण निर्देश-प्रशिक्षण, वर्गीकरण और क्षेत्रीय अनुकूलन में सहायक होते हैं।
- संरेखण/RLHF (मानवीय प्रतिक्रिया से सुदृढीकरण शिक्षण): मानव मूल्यांकनकर्ता मॉडल के आउटपुट को रैंक करते हैं ताकि यह अधिक सुरक्षित, सटीक और मानवीय उद्देश्य के अनुरूप बने, तथा हानिकारक या पक्षपाती प्रतिक्रियाओं को हतोत्साहित किया जा सके।
भारत में LLM प्रशिक्षण की चुनौतियाँ
- भारतीय भाषाओं में सीमित डाटा: उच्च-गुणवत्ता वाले डाटा सेट की कमी मॉडल के प्रदर्शन को घटाती है।
- कई प्रणालियाँ पहले अंग्रेज़ी में अनुवाद पर निर्भर करती हैं, जिससे टोकन उपयोग और विलंबता बढ़ती है। मूल भाषाओं में कमज़ोर प्रदर्शन गैर-अंग्रेज़ी उपयोगकर्ताओं के बीच अपनाने को प्रभावित करता है।
- उच्च पूंजीगत आवश्यकताएँ: अग्रणी मॉडल का प्रशिक्षण भारी वित्तीय निवेश मांगता है। स्टार्टअप्स के पास प्रायः तत्काल व्यावसायिक लाभ नहीं होते जो ऐसे व्यय को उचित ठहरा सकें।
- बुनियादी ढाँचे की सीमाएँ: उच्च-स्तरीय संगणनात्मक सुविधाओं तक पहुँच सरकार के समर्थन के बिना सीमित रहती है।
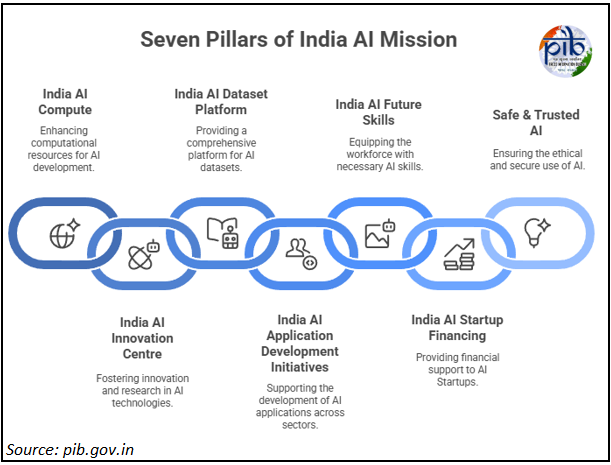
इंडियाएआई मिशन
- इंडियाएआई मिशन भारत के लिए एक व्यापक, स्वदेशी AI पारिस्थितिकी तंत्र बनाने की प्रमुख पहल है।
- यह उच्च-प्रदर्शन संगणनात्मक बुनियादी ढाँचे, स्वदेशी आधारभूत मॉडल और सुरक्षित, नैतिक AI के विकास पर केंद्रित है, “भारत में AI बनाना एवं भारत के लिए AI को कार्यशील बनाना” की दृष्टि के अंतर्गत।
- भारत ने 38,000 GPUs प्राप्त किए हैं, जो विश्व-स्तरीय AI संसाधनों तक सुलभ और किफ़ायती पहुँच प्रदान करते हैं।
- GPU या ग्राफिक्स प्रोसेसिंग यूनिट एक शक्तिशाली कंप्यूटर चिप है जो मशीनों को तीव्रता से सोचने, चित्रों को संसाधित करने, AI प्रोग्राम चलाने और जटिल कार्यों को सामान्य प्रोसेसर की तुलना में अधिक दक्षता से संभालने में सक्षम बनाता है।
स्रोत: TH
Previous article
ऊर्जा असंतुलन और एल नीनो की बदलती गतिशीलता
Next article
ब्लॉकचेन आधारित डिजिटल शासन